
On June 9, Anthropic released two AI products built on one underlying model. Claude Fable 5 is available to the public. Claude Mythos 5 is the same model with fewer restrictions, and it is reserved for vetted cybersecurity partners and approved life-sciences researchers.1,3,4
That structure is the actual news. Frontier AI labs have always tuned one product for everyone, balancing capability against misuse risk with a single dial. This release splits the dial. The general public gets a heavily safeguarded version. Trusted institutions get more of the full model. One analysis called it the frontier "split in two," and that framing is right.7
For healthcare, this is not an abstract AI-industry story. The three domains where this model family shows its largest gains, and where Anthropic drew its hardest access lines, are health reasoning, biology, and cybersecurity. Healthcare organizations live in all three at once.
What actually shipped
Anthropic positions the pair as its most capable models to date, with state-of-the-art results across coding, knowledge work, vision, and long-context tasks.1,6 Fable 5 is rolling out across the Claude apps, the API at $10 per million input tokens and $50 per million output tokens, and cloud platforms including AWS Bedrock. It is included at no extra cost on paid Claude plans from June 9 through June 22, which matters for anyone who wants to evaluate it before committing budget.1,9
The safeguard architecture is the distinctive part. Fable 5 carries safety classifiers for cybersecurity and for biology and chemistry. When a request trips one of those classifiers, the system does not simply refuse. It falls back to Claude Opus 4.8, the previous flagship, and answers with that model instead. Anthropic reports that more than 95 percent of sessions never encounter a fallback, and that an external bug bounty spanning more than 1,000 hours of testing found no universal jailbreaks.1,5
Mythos 5 removes those restrictions in specific domains for specific users: cybersecurity professionals through a trusted-access program called Project Glasswing, and selected biomedical researchers through parallel vetting.1,2,5
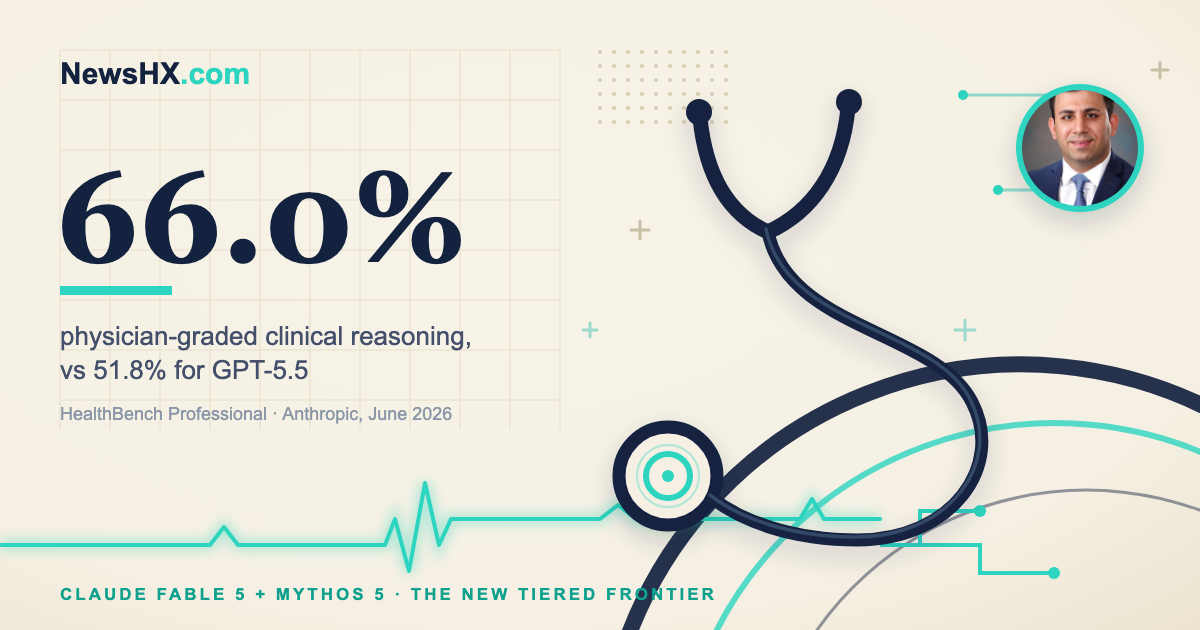
The health numbers, and the asterisk next to them
On HealthBench Professional, a benchmark of physician-graded clinical conversations and reasoning, the new model family scores 66.0 percent. That compares with 56.9 percent for Claude Opus 4.8 and 51.8 percent for GPT-5.5. It is the largest single-generation jump on that benchmark Anthropic has reported, and it puts meaningful distance between this model and everything else on the published table.1
But that 66.0 percent carries an asterisk, and the asterisk is where healthcare teams should slow down. Anthropic's own methodology note explains that starred benchmarks, which include health, biology, and cybersecurity, show a larger gap between Mythos 5 and Fable 5 because of the blocking safeguards. On those benchmarks, the publicly available Fable 5 performs closer to Opus 4.8, because flagged queries are answered by the fallback model.1,7
In plain language: the headline health number describes the restricted model. The model your organization can actually buy today will deliver that performance on most health queries, and previous-generation performance on whatever subset the biology classifier decides is sensitive. Anthropic says it intends to narrow the safeguards over time. Until then, clinical and pharma teams face some routing uncertainty, and they should test for it rather than assume it away.7
Operational takeaway: if you are evaluating Fable 5 for clinical decision support, medical affairs, or research synthesis, your pilot should measure two things separately. First, raw quality on your tasks. Second, how often your legitimate queries trigger the biology fallback, because that determines which model is actually answering your clinicians.
Biology: the dual-use line runs through medicine
The biology results are the most striking in the release, and the most carefully gated. On BioMysteryBench, a benchmark of difficult biology research problems, the model family scores 46.1 percent on the hard tier versus 40.0 percent for Opus 4.8, and 83.9 percent on problems human experts have solved.1
The applied claims go further. Anthropic reports that Mythos 5 accelerated a partner's protein design process roughly tenfold and identified 9 of 14 strong drug candidates in a discovery screen. In blind comparisons, its molecular biology hypotheses were preferred about 80 percent of the time, and at least one model-generated hypothesis was later independently corroborated by experimental work.1,6
Those are vendor-reported numbers from selected partnerships, and they deserve the same skepticism any sponsored result gets. But the direction is consistent with what the field has watched build for two years: frontier models are becoming genuine instruments for hypothesis generation and molecular design, not just literature summarizers.
The same capability is why the gate exists. Tools that design useful proteins can, in principle, assist with harmful ones. Anthropic's answer is structural: the public model broadly declines dual-use biology and falls back to Opus 4.8, while approved researchers apply for deeper access through trusted programs.1,2 The honest criticism, raised in early analysis, is that the classifier is currently broad enough to catch legitimate biomedical work, and the promised narrowing has not shipped yet.7 Both things are true. The gate is defensible, and it currently has a false-positive problem that real research teams will feel.
Cybersecurity: defenders get the strong model first
The cybersecurity numbers show the same split in sharper relief. On ExploitBench, which measures offensive capability, the model family scores 78.0 percent versus 40.0 percent for Opus 4.8 and 34.0 percent for GPT-5.5. That is nearly double the previous generation. And on the public Fable 5, essentially none of it is reachable: exploitation and offensive cyber requests are blocked outright and routed to the fallback model.1,5,7
Access to the full capability flows through Project Glasswing, which Anthropic recently expanded to roughly 150 vetted organizations, including Dragos, Tenable, Trend Micro, Netskope, BeyondTrust, Rubrik, and BT.5 The explicit bet is asymmetry: give defenders the strongest model for vulnerability research, detection engineering, and incident response, while denying the same capability to anonymous users.
Healthcare should care about this bet more than any other industry, because healthcare is the target. The FBI's 2025 Internet Crime Report again identified healthcare and public health as the most targeted critical infrastructure sector for ransomware, ahead of every other sector tracked.8 Hospitals combine digitally dependent care delivery, patient safety obligations, and zero tolerance for downtime, which is exactly the profile attackers prefer.
The question for healthcare is no longer whether frontier AI is capable enough. It is who gets which version, and who decides.
If the defender-first model works, health systems benefit indirectly and quickly, because the security vendors protecting hospital networks are on the Glasswing list. If it fails, it fails in a familiar way: capability leaks, attackers adapt, and under-resourced hospital security teams face AI-assisted adversaries without AI-assisted defense. Health system CISOs should be asking their security vendors a new question this quarter: do you have trusted access to frontier models, and what are you doing with it on our behalf?
How we are testing it at NewsHX
NewsHX runs its editorial research on a Claude-based pipeline: structured literature scans, source retrieval, citation verification against publisher records, and data extraction from published figures, all under physician editorial review before anything ships under my byline. Every claim in every research piece is checked against its primary source, and the model does the first pass of that checking.
We began testing Fable 5 inside that pipeline on release day, side by side against Opus 4.8, on three tasks that map to the benchmark claims. First, reference verification: whether the model correctly flags mismatches between an article's numbers and the cited paper. Second, figure extraction, since the vision gains Anthropic reports are directly relevant to pulling data out of published charts and tables.1 Third, synthesis across long policy and guideline documents, where the long-context improvements should show up as fewer dropped details.
We are also logging something the benchmarks cannot tell us: how often legitimate clinical and biomedical queries trip the biology fallback in real editorial work. That number, not the headline score, will determine how useful the public model is for healthcare research teams. We will publish what we find.
Full disclosure, and a fitting one: this article was researched, fact-checked, and assembled with that same pipeline, with the new model in the loop, under human editorial review. The tool covered the ground. The judgment, and the byline, remain human.
What health leaders should take from this
First, tiered access is now the operating model for frontier AI, not an experiment. Capability and safety are no longer tuned with one dial for one audience, and procurement teams should expect "which version, under which access program" to become a standard diligence question.7
Second, the free evaluation window through June 22 is a genuine opportunity. Run your own tasks against it now, measure the fallback rate on your real queries, and make the upgrade decision on your data rather than the vendor's table.1
Third, watch the safeguard narrowing. The gap between what the restricted model can do in biology and what the public model will do for your researchers is the single most important variable for health-sector value, and it is the one Anthropic has explicitly promised to move.1,7
The frontier did not just get more capable this week. It got more governed. Healthcare, which sits at the center of every domain this release touches, should treat that as the headline.
Deciding how frontier AI fits into your clinical, research, or security operation?
A3HCS helps healthcare organizations evaluate AI capability claims, build governance that survives contact with real clinical workflows, and separate vendor noise from operational value.
Start the conversation at A3HCS.orgReferences
- Anthropic. “Claude Fable 5 and Claude Mythos 5.” June 9, 2026. anthropic.com/news/claude-fable-5-mythos-5
- Anthropic. “Claude Mythos.” anthropic.com/claude/mythos
- CNBC. “Anthropic releases Mythos-like AI model to the public, Claude Fable 5.” June 9, 2026. cnbc.com/2026/06/09/anthropic-mythos-claude-fable-5.html
- NBC News. “Anthropic releases Fable 5, the first public Mythos-class model.” June 2026. nbcnews.com/tech/security/fable-5-anthropic-release-public-mythos-claude-model-rcna349104
- SecurityWeek. “Anthropic Launches Claude Fable 5: Mythos-Class AI With Cybersecurity Guardrails.” June 2026. securityweek.com/anthropic-launches-claude-fable-5-mythos-class-ai-with-cybersecurity-guardrails/
- The Decoder. “Anthropic releases Claude Fable 5 and Mythos 5 with major gains in coding and science.” June 2026. the-decoder.com/anthropic-releases-claude-fable-5-and-mythos-5-with-major-gains-in-coding-and-science/
- Digital Applied. “Claude Fable 5 & Mythos 5: The Frontier, Split in Two.” June 2026. digitalapplied.com/blog/claude-fable-5-mythos-5-release-benchmarks-2026
- FBI Internet Crime Complaint Center. “2025 Internet Crime Report.” 2026. ic3.gov/AnnualReport/Reports/2025_IC3Report.pdf
- Amazon Web Services. “Anthropic Claude Fable 5 on AWS: Mythos-class capabilities with built-in safeguards now available.” June 2026. aws.amazon.com/blogs/aws/anthropic-claude-fable-5-on-aws-mythos-class-capabilities-with-built-in-safeguards-now-available/